∆¸µ≠/2020-6-2§Ë§Í¡∞§Œ5∆¸ ¨
2020-4-22
RakutenBooksSearch •◊•È•∞•§•Û
°°
°°∫Ú«Ø° 2019«Ø°ÀAmazon•¢•Ω•∑•®•§•»°¶•◊•Ì•∞•È•ý§ŒPA-API° Product Advertising API°À§ŒÕ¯Õ—µ¨ÃÛ§¨ —ππ§µ§Ï°¢PA-API§Œ•Í•Û•Ø§Ú≤§∑§ø«‰§Íæ§≤§¨»Ø¿∏§∑§ §§•µ•§•»§«§œPA-API§¨ª»§®§ §Ø§ §Í§Þ§∑§ø°£AmazonSearch •◊•È•∞•§•Û§«§œPA-API§Ú√°§§§∆§§§Î§Œ§«§π§¨°¢§¶§¡§þ§ø§§§ «‰§Íæ§≤§ §Û§´¡¥§Ø§ §§ºÂæÆ•¶•ß•÷•µ•§•»§«§œ§π§∞§Àª»§®§ §Ø§ §√§∆§∑§Þ§§§Þ§∑§ø°£
°°§Ω§Ï§´§È∞Ï«Ø∞ 槀§√§»§§§ø§Ô§±§«§π§¨°¢§≥§Œ§»§≥§Ì§‰§Î§≥§»§‚§ §Ø§∆•“•Þ§ §Œ§«°¢PA-API§À¬Â§Ô§Í°¢≥⁄≈∑•÷•√•Ø•π¡ÌπÁ∏°∫˜API§ÚÕ—§§§ø涅 ∏°∫˜§Œ∑Î≤Ã§Ú…Ωº®§π§ÎFreeStyleWiki§Œ•◊•È•∞•§•Û§Ú∫ӿƧ∑§∆§þ§Þ§∑§ø°£
•§•Û•π•»°º•Î
- ≥⁄≈∑•¶•ß•÷•µ°º•”•π§Œø∑µ¨•¢•◊•Í≈–œø§Œ•⁄°º•∏§´§È°¢ø∑µ¨•¢•◊•Í§Ú≈–œø§∑°¢applicationId°¢affiliateId§ÚºË∆¿§∑§Þ§π°£
- ∞ ≤º§Œ•’•°•§•Î§Ú•¿•¶•Û•Ì°º•…§∑§Þ§π°£
- rakutensearch.zip(276)
- RakutenBooksSearch.pm§Œ86π‘ÃЧÀapplicationId§Ú°¢87π‘ÃЧÀaffiliateId§Ú§Ω§Ï§æ§Ï¿þƒÍ§∑§Þ§π°£
- plugin∞ ≤º§À•§•Û•π•»°º•Î§∑§Þ§π°£
- § §™°¢≥⁄≈∑•÷•√•Ø•π¡ÌπÁ∏°∫˜API§œHTTPS§«§¢§Î§ø§·°¢LWP::UserAgent§¨•¢•Ø•ª•π§π§Î§ø§·§À§œLWP::Protocol::https§¨…¨Õ◊§»§ §Î§≥§»§À√Ì∞’§¨…¨Õ◊°£π¨§§§≥§Œ•µ•§•»§¨•€•π•»§µ§Ï§∆§§§Î§µ§Ø§È•§•Û•ø°º•Õ•√•»§Œ•Þ•∑•Û§À§œ§¢§È§´§∏§·§≥§Œ•‚•∏•Â°º•Î§¨•§•Û•π•»°º•Î§µ§Ï§∆§§§ø§ø§·°¢ø∑§ø§À•§•Û•π•»°º•Î§π§Î§ §…§Œ¬–±˛§œ…¨Õ◊§ §´§√§ø°£
ª»§§ ˝
{{rakutenbookssearch ≈ÏÃÓ∑Ω∏„,b,10,m}}
- °÷≈ÏÃÓ∑Ω∏„°◊§œ∏°∫˜∏ϧ«…¨øЧŒ•—•È•·°º•ø°£
- °÷b°◊§œæ¶… §Œ•∏•„•Û•Î§«∞ ≤º§ŒºÔŒý§¨§¢§Î°£æ Œ¨ª˛§œa°£
| •—•È•·°º•ø | •∏•„•Û•Î |
|---|---|
| a | §π§Ÿ§∆ |
| b | Book |
| c | CD |
| d | DVD |
| s | Software |
| f | Foreign Book |
| g | Game |
| m | Magazine |
- °÷10°◊§œ∑Î≤çŒøÙ§«æ Œ¨≤ƒ«Ω°£æ Œ¨ª˛§œ1°£∫«¬Á√Õ§œ30°£
- °÷m°◊§œΩÒ±∆§Œ•µ•§•∫§«°¢s°¢m°¢l§´§È¡™§Ÿ§Î°£æ Œ¨ª˛§œs°£
 | |
| «Úƒª§»•≥•¶•‚•Í° æ°À° ≤º°À•ª•√•» | |
| ∏∏≈þºÀ | |
| ≈ÏÃÓ ∑Ω∏„ | |
| ≥⁄≈∑ Amazon | |
 | |
| «Úƒª§»•≥•¶•‚•Í° æ°À | |
| ∏∏≈þºÀ | |
| ≈ÏÃÓ ∑Ω∏„ | |
| ≥⁄≈∑ Amazon | |
 | |
| •Ø•π•Œ•≠§ŒΩ˜ø¿ | |
| º¬∂»«∑∆¸Àк“ | |
| ≈ÏÃÓ°°∑Ω∏„ | |
| ≥⁄≈∑ Amazon | |
 | |
| «Úƒª§»•≥•¶•‚•Í° ≤º°À | |
| ∏∏≈þºÀ | |
| ≈ÏÃÓ ∑Ω∏„ | |
| ≥⁄≈∑ Amazon | |
 | |
| •÷•È•√•Ø°¶•∑•Á°º•Þ•Û§»≥–¿√§π§ÎΩ˜§ø§¡ | |
| ∏˜ ∏º“ | |
| ≈ÏÃÓ∑Ω∏„ | |
| ≥⁄≈∑ Amazon | |
 | |
| •÷•È•√•Ø°¶•∑•Á°º•Þ•Û§»Ã槂§ §≠ƒÆ§Œª¶øÕ | |
| ∏˜ ∏º“ | |
| ≈ÏÃÓ∑Ω∏„ | |
| ≥⁄≈∑ Amazon | |
 | |
| «Ú∂‰•∏•„•√•Ø°°ø∑¡ı»« | |
| º¬∂»«∑∆¸Àк“ | |
| ≈ÏÃÓ°°∑Ω∏„ | |
| ≥⁄≈∑ Amazon | |
 | |
| §¢§ §ø§¨√ا´§Úª¶§∑§ø | |
| π÷√ú“ | |
| ≈ÏÃÓ ∑Ω∏„ | |
| ≥⁄≈∑ Amazon | |
 | |
| ¿„±Ï•¡•ß•§•π°°ø∑¡ı»« | |
| º¬∂»«∑∆¸Àк“ | |
| ≈ÏÃÓ°°∑Ω∏„ | |
| ≥⁄≈∑ Amazon | |
 | |
| ≈ÏÃÓ∑Ω∏„∏¯º∞•¨•§•…°°∫Ó≤»¿∏≥Ë35º˛«Øver°• | |
| π÷√ú“ | |
| ≈ÏÃÓ∑Ω∏„∫Ó≤»¿∏≥Ë35º˛«Øº¬π‘∞—∞˜≤Ò | |
| ≥⁄≈∑ Amazon |
‰¬≠
- ≥⁄≈∑§¿§±§«§ §Ø°¢§ƒ§§§«§ÀAmazon§ÿ§Œ•Í•Û•Ø§‚§ƒ§±§∆§þ§ø§¨°¢
13∑§ŒISBN§‰JAN•≥°º•…§´§ÈÃµÕ˝ÃÕ˝∏°∫˜§∑§ø∑Î≤猕⁄°º•∏§ÿ§Œ•Í•Û•Ø§À§ §√§∆§§§Î°£JAN•≥°º•…§œÃµÕ˝ÃÕ˝∏°∫˜§∑§ø∑Î≤猕⁄°º•∏§¿§¨°¢13∑§ŒISBN§œ10∑§À —¥π§∑§∆§π§√§≠§Í§∑§øURL§ÿ§Œ•Í•Û•Ø§À§∑§ø°£§≥§Ï§«µˆ§∑§∆§Ø§¿§µ§§°£ - •◊•È•∞•§•Û§ŒΩ–Œœ¡¥¬Œ§Ú <div class="rakutensearch">°¡</div> §«§Ø§Î§Û§«§¢§Í§Þ§π°£•∆°º•÷•Î§Ú¡»§Û§«…Ωº®§∑§∆§§§Þ§π§Œ§«°¢œ»¿˛§¨§¶§Î§µ§Ø¥∂§∏§ÎæÏπÁ§À§œCSS§«»Û…Ωº®§À§∑§∆§Ø§¿§µ§§°£
div.rakutensearch table, div.rakutensearch th, div.rakutensearch td, div.rakutensearch img {
border-style:none;
}
- ≈ˆΩȧœ°¢≥⁄≈∑涅 ∏°∫˜API§Úª»§√§∆°¢≥⁄≈∑ª‘æϧŒæ¶… §Ú∏°∫˜§π§Î•◊•È•∞•§•Û§‚∫ӧ̧¶§»ª◊§√§∆§ø§Œ§«§π§¨°¢≥⁄≈∑•÷•√•Ø•π§¿§±§«ΩΩ ¨§ ¥∂§∏§¨§∑§∆§‰§·§∆§∑§Þ§§§Þ§∑§ø°£µ§§¨∏˛§§§ø§È∫ӧΧ´§‚§∑§Ï§Þ§ª§Û°£
- PA-API§¨ª»§®§ §§ÀЕµ•§•»§«§œ°¢AmazonSearch •◊•È•∞•§•Û§ÚΩÒ§≠¥π§®§∆°¢∆‚…Ù§«RakutenBooksSearch •◊•È•∞•§•Û§Ú∏∆§÷§Ë§¶§À§∑§∆§þ§Þ§∑§ø°£§≥§Ï§«¥˚¬∏§Œ•⁄°º•∏§Àµ≠∫Чµ§Ï§∆§§§ÎAmazonSearch •◊•È•∞•§•Û§Œ…Ù ¨§«§‚§Ω§Ï§√§ð§§…Ωº®§¨§ §µ§Ï§Î§Ë§¶§À§ §Î§œ§∫°£
2020-3-22
2020«Ø§Œ∫˘
°°







2020/03/22° ∆¸°Àª£±∆
2019-3-9
Þ˚¿–§»¿…œ”§Œ≥ÿ¿∏°¶¬≥¬≥
°°
°°°÷Þ˚¿–ª≥ÃÆ ∏Ω¬Â∆¸ÀЧŒ¡√§Ú√€§§§ø°ÿª’ƒÔ∞¶°Ÿ°◊§Ú∆…Œª° ∞ ≤º°÷Þ˚¿–ª≥ÃÆ°◊°À°£
°°§≥§ŒÀЧŒ√ʧ«°¢°÷Þ˚¿–§»¿…œ”§Œ≥ÿ¿∏°◊§«ºË§Íæ§≤§ø°¢Þ˚¿–§¨≈ϵ˛ƒÎπÒ¬Á≥ÿ§«π÷ª’§Ú§∑§∆§§§øª˛§ÀµØ§≠§ø°÷≤˚ºÍªˆ∑Ô°◊§À§ƒ§§§∆ø®§Ï§È§Ï§∆§§§ø°£
°°ª‰∏´§À§Ë§Ï§–°¢°÷≤˚ºÍªˆ∑Ô°◊§À§œ°¢§Ω§ŒæϧÀµÔπÁ§Ô§ª§ø∆ÛøÕ§¨§Ω§Ï§æ§Ïæߧ®§∆§§§Î°¢øπ≈ƒ¡ ø¿‚°¢∂‚ª“∑Ú∆Û¿‚§Œ∆Û§ƒ§Œ¿‚§¨§¢§Î°£
°°øπ≈ƒ¿‚§œ°¢ªˆ∑Ô§Œ»Ø¿∏∆¸§œÃ¿º£38«Ø11∑Ó10∆¸§¥§Ì§«°¢¿…œ”§Œ≥ÿ¿∏° ∏«ذ¢µ˚Ωª∆◊µ»§¿§»§§§¶§≥§»§¨Ã¿§È§´§À§ §Î°À§À¬–§∑§∆§Ω§¶§»√Œ§È§∫§ÀæÆ∏¿§Ú∏¿§√§∆§∑§Þ§√§øÞ˚¿–§¨°¢∂≤Ωç∑§∆°÷ÀÕ§‚ÀË∆¸Ãµ§§√“∑≈§Ú𠧃§∆π÷µ¡§Ú§∑§∆§§Î§Û§¿§´§È°¢∑ا‚§ø§Þ§À§œÃµ§§œ”§«§‚Ω–§∑§ø§È§Ë§´§È§¶°◊§»§§§¶∞Ï∏¿§Úœ≥§È§∑§ø°¢§»§§§¶§‚§Œ°£
°°¬–§∑§∆∂‚ª“¿‚§«§œ°¢ªˆ∑Ô§¨µØ§≠§ø§Œ§œøπ≈ƒ¿‚§Ë§Í∞ϫا€§…¡∞§ŒÃ¿º£37«Ø12∑Ó1∆¸°£≤˚ºÍ§Œ≥ÿ¿∏§À√Ì∞’§∑§øÞ˚¿–§œ°¢§Ω§Œ≥ÿ¿∏§¨¿…œ”§«§¢§Î§≥§»§Ú√Œ§Î§»°¢≤ø§‚∏¿§Ô§∫§Ω§Œ§Þ§Þ∂µºº§´§ÈΩ–§∆π‘§√§ø§≥§»§À§ §√§∆§§§Î°£
°°∂‚ª“¿‚§œ°¢§Ω§Ï§¨µ≠§µ§Ï§ø∂‚ª“§Œ√¯ΩÒ°÷øÕ¥÷Þ˚¿–°◊§Œ°¢∑Ô§Œ≥ÿ¿∏§Œ√ ™§Œøß ¡§‰…Ωæ§ §…°¢∫Ÿ…Ù§ÀªÍ§ÎæÐ∫Ÿ§ µ≠∫Ч¨øÆÿ·¿≠§Œπ‚§µ§Ú¥∂§∏§µ§ª°¢§Ω§Œ§ø§·°¢Þ˚¿–§Œ∞Ï∏¿§œÀÐ≈ˆ§œ§ §´§√§ø°¢∏«Ø√ا´§À§Ë§√§∆¡œ∫Ó§µ§Ï§ø§‚§Œ§¿°¢§»§§§¶œ√§Œ∫¨µÚ§»§ §√§∆§§§Î°£
°°§∑§´§∑§ §¨§È°¢Þ˚¿–º´ø»§¨Ã¿º£38«Ø11∑Ó13∆¸§ÀÃÓ¬º≈¡ªÕ§ÀΩ–§∑§øª‰øƧ«°÷∂·∫¢º∫∑…§ŒªÍ°◊§»§∑§∆ªˆ∑Ô§Àø®§Ï°¢∫«∏§Œ∞Ï∏¿§‚µ≠§∑§∆§§§Î°£ªˆ∑Ô§´§È∞Ï«Ø∞ æÂ∑–§√§∆§§§Îª‰øƧ«§Ω§Ï§Ú°÷∂·∫¢°◊§Œ§≥§»§¿§»§π§Î§Œ§´°¢§»§§§¶µøɧ´§È°¢§≥§ŒÕ’ΩÒ§œ∂‚ª“¿‚§ŒøÆÿ·¿≠§ÚÕ…§Î§¨§π§‚§Œ§»§ §√§∆§§§Î°£
°°∑Î∂…°¢øπ≈ƒ¿‚°¢∂‚ª“¿‚§Œ§§§∫§Ï§¨ÀÐ≈ˆ§Œ§≥§»§ §Œ§´§Ô§´§È§ §§°¢§»§§§¶§Œ§¨°¢°÷Þ˚¿–§»¿…œ”§Œ≥ÿ¿∏°◊§Àµ≠§∑§ø∑Îœ¿§«§¢§√§ø°£
°°°÷Þ˚¿–ª≥ÃÆ°◊§«°¢…ƺ‘§Œƒπ»¯π‰§œ°¢øπ≈ƒ¿‚§»∂‚ª“¿‚§Œ¿Þ√Ô∞∆§»§‚∏¿§®§Î¿‚§Úæߧ®§∆§§§Î° §Ë§¶§Àª‰§À§œª◊§®§Î°À°£
°°ƒπ»¯§œ°¢¥ÀÐ≈™§À§œ∂‚ª“¿‚§À±Ë§§§ §¨§È§‚°¢
µ˚Ωª§Œ¿ §»∂‚ª“§Œ¿ §¨Œ•§Ï§∆§§§ø§ø§·Þ˚¿–§¨Ãµ∏¿§¿§√§ø§Ë§¶§À∏´§®§ø§¿§±§«§¢§Ì§¶
§»§∑§∆°¢∫«∏§Œ∞Ï∏¿§œ§¢§√§ø°¢§»§∑§∆§§§Î°£
°°§Ω§∑§∆°¢Þ˚¿–§¨ªˆ∑Ô§´§È∞Ï«Ø∏§ÀΩ–§∑§øª‰øƧ«°¢ªˆ∑Ô§¨°÷∂·∫¢°◊§Œ§≥§»§¿§»§∑§ø§Œ§œ°¢
µ˚Ωª§Œ∑Ô§œ°¢æا §Ø§»§‚∞Ï«Ø∂·§Ø°¢Þ˚¿–§À§»§√§∆¿∏°π§∑§§°÷√—§∫§Ÿ§≠µ≠≤±°◊§»§∑§∆¬≥§§§∆§§§ø§Ë§¶§«§¢§Î°£
§»§ŒÕ˝Õ≥§¿§»≤Úº·§∑§∆§§§Î°£
°°§Þ§¢°¢§≥§Œ ’§¨§¶§Þ§§ÕÓ§»§∑Ωͧ´§ °¢§»ª‰§‚ª◊§¶° ¿º§¨ π§≥§®§ §§§Ø§È§§Œ•§Ï§ø¿ §«°¢§ §º√ ™§Œøß ¡§‰≥ÿ¿∏§Œ…Ωæ§Þ§«§Ô§´§√§ø§Œ§´°¢§»§§§¶µøɧœªƒ§Î§¨°À°£
°°ªˆ∑Ô§À¥ÿ§∑§∆°¢§≥§Œ§Ë§¶§ °÷§Ω§Ï§È§∑§§≤Úº·°◊§¨§ §µ§Ï§øΩÒ ™§¨¿§§ÀΩ–§ø°¢§»§§§¶§≥§»§œ°¢§ §Û§¿§´¥Ó§–§∑§§°¢§»º´ ¨æ°ºÍ§Àª◊§¶º°¬Ë°£
2019-2-28
Google•´•Ï•Û•¿°º§À•◊•ÌÃӵ§Œ∆¸ƒ¯§Ú•§•Û•ð°º•»§π§Î§ø§·•π•Ø•Ï•§•‘•Û•∞°¶¬≥
°°
°°∞Ï∫Ú∆¸°¢Google•´•Ï•Û•¿°º§À•◊•ÌÃӵ§Œ∆¸ƒ¯§Ú•§•Û•ð°º•»§π§Î ˝À°§Úæ“≤§∑§ø§¨°¢Python§Œ§≥§»§Ú§Ë§Ø√Œ§È§ §§ª‰§œ°¢¿§§Œ√ʧÀ§œpandas§»§§§¶ ÿÕ¯§ •‚•Œ§¨§¢§Î§≥§»§Ú√Œ§È§ §´§√§ø°£§≥§Ï§ÚÕ—§§§∆•π•Ø•Í•◊•»§ÚΩÒ§≠ƒæ§∑§∆§þ§ø§È°¢§´§ §Í§π§√§≠§ÍΩҧا≥§»§¨§«§≠§∆À˛¬≠°£§«§‚°¢§Þ§¢°¢§≥§Ï§Þ§øΩ¨∫Ó§»§§§¶§≥§»§«°£
#!/usr/bin/python3
#coding: utf-8
#scrapingnpb2.py
import sys
import re
import datetime
import pandas
import pprint
print("Subject, Start Date, Start Time, End Date, End Time, Description, Location")
months = ['03', '04', '05', '06', '07', '08', '09']
# 0, 1, 2, 3, 4, 5
#(0, '3/29° ∂‚°À', 'DeNA - √Ê∆¸', '≤£\u3000…Õ 18:30', nan, nan)
for month in months:
url = "http://npb.jp/games/2019/schedule_" + month + "_detail.html"
tb = pandas.io.html.read_html(url)
for row in tb[0].itertuples(name=None):
card = ''
md = re.sub(r'° .*°À', '', row[1])
ymd = '2019/' + md
sttm = ''
entm = ''
place = ''
if row[2] == row[2]:
card = re.sub(' - ', '¬–', row[2])
if row[3] == row[3]:
place_time = row[3].split(' ')
if len(place_time) > 1:
(sthr, stmn) = place_time[1].split(':')
(mon, day) = md.split('/')
start = datetime.datetime(2019, int(mon), int(day), int(sthr), int(stmn), 0)
delta = datetime.timedelta(minutes=200)
end = start + delta
sttm = start.strftime("%H:%M:%S")
entm = end.strftime("%H:%M:%S")
place = re.sub(r'\s+', '', place_time[0])
else:
sttm = '18:00:00'
entm = '21:20:00'
place = place_time[0]
if len(sys.argv) > 1:
m = re.search(sys.argv[1], card)
if m:
print(f"{card}, {ymd}, {sttm}, {ymd}, {entm}, {card}, {place}")
elif card != '':
print(f"{card}, {ymd}, {sttm}, {ymd}, {entm}, {card}, {place}")
°°ª»§§ ˝§œ°÷./scrapingnpb2.py°◊°¢§‚§∑§Ø§œ°÷./scrapingnpb2.py ∫Âø¿°◊§»§§§¶…˜§ÀµÂ√ƒÃæ§ÚÕø§®§Î°£≤ø§‚Õø§®§ §§§»§π§Ÿ§∆§Œ∆¸ƒ¯§¨°¢µÂ√ƒÃæ§ÚÕø§®§Î§»§Ω§ŒµÂ√ƒ§Œ§þ§Œ∆¸ƒ¯§¨Ω–Œœ§µ§Ï§Î°£
°°Ω–Œœ∑Î≤çÚcsv•’•°•§•Î§»§∑§∆ ð¬∏§∑°¢Google•´•Ï•Û•¿°º§À•§•Û•ð°º•»§π§Ï§–OK°£
°°∫Âø¿•ø•§•¨°º•π§Œ∏¯º∞•µ•§•»§ŒªÓπÁ∆¸ƒ¯§Œ•⁄°º•∏§œtable•ø•∞§¨ª»§Ô§Ï§∆§§§ §§§ø§·°¢∞¬ƒæ§Àpandas§œª»§®§ §´§√§ø°£ªƒ«∞°£
2019-2-27
Google•´•Ï•Û•¿°º§À∫Âø¿•ø•§•¨°º•π§ŒªÓπÁ∆¸ƒ¯§Ú•§•Û•ð°º•»§π§Î§ø§·•π•Ø•Ï•§•‘•Û•∞
°°
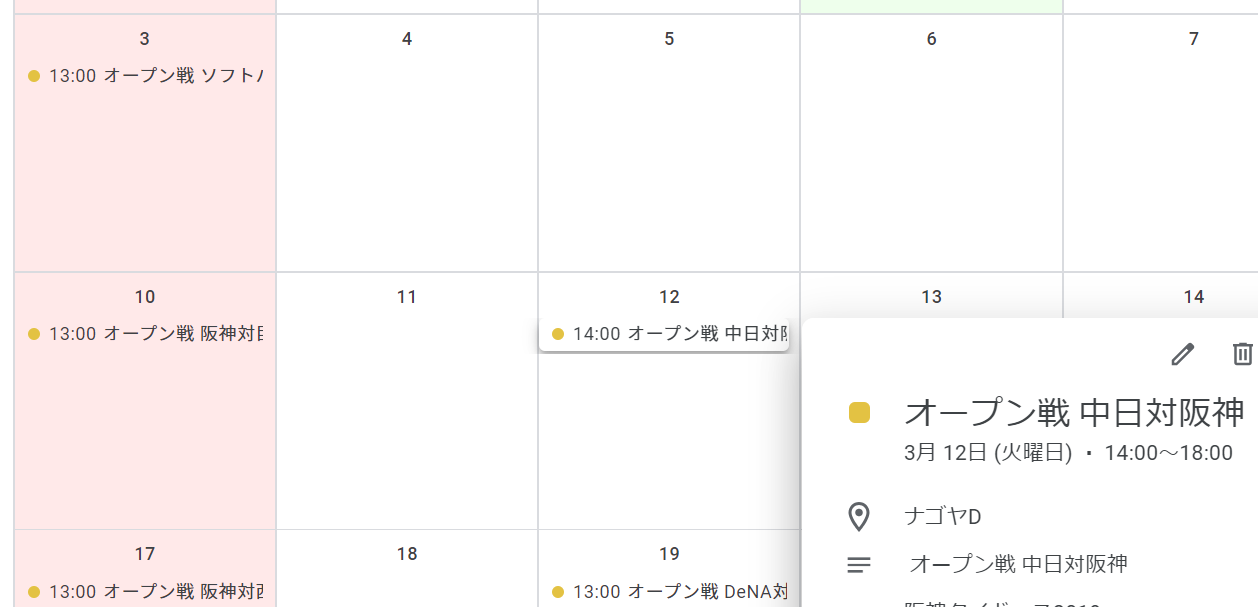
°°
°°∫Ú∆¸°¢Google•´•Ï•Û•¿°º§À•◊•ÌÃӵ§Œ∆¸ƒ¯§Ú•§•Û•ð°º•»§π§Î ˝À°§Úæ“≤§∑§ø§¨°¢•π•Ø•Ï•§•‘•Û•∞§Œæ Û∏ª§Œ∆¸ÀÐÃӵµ°πΩ§ŒªÓπÁ∆¸ƒ¯§Œ•⁄°º•∏§À§œ°¢∏¯º∞¿Ô§Œ∆¸ƒ¯§∑§´∫Ч√§∆§§§ §§°£
°°ª‰§œ∫Âø¿•’•°•Û§ §Œ§¿§¨°¢§π§«§Àªœ§Þ§√§∆§§§Î•™°º•◊•Û¿Ô§Œæ Û§‚§º§“∫Чª§ø§§§»ª◊§§°¢∫Âø¿•ø•§•¨°º•π§Œ∏¯º∞•µ•§•»§ŒªÓπÁ∆¸ƒ¯§Œ•⁄°º•∏§Ú•π•Ø•Ï•§•‘•Û•∞§∑§∆° •π•Ø•Ï•§•‘•Û•∞§Œ§∑§‰§π§µ§´§È°¢•±°º•ø•§∏˛§±§Œ•⁄°º•∏§Úª≤滧∑§∆§§§Î°À°¢ªÓπÁ∆¸ƒ¯§Œæ Û§Ú•≤•√•»§∑°¢§≥§Ï§ÚGoogle•´•Ï•Û•¿°º§À…Ωº®§∑§∆§þ§ø°£
°°•π•Ø•Ï•§•‘•Û•∞§π§Î•π•Ø•Í•◊•»§œ Ÿ∂Ø√ʧŒPython§«ΩÒ§§§∆§þ§ø°£§≥§Ï§Þ§øΩ¨∫Ó§»§§§¶§≥§»§«°£
#!/usr/bin/python3
#coding: utf-8
#scrapingtigers.py
import re
import datetime
import urllib.request
import pprint
from bs4 import BeautifulSoup
data = {}
team = {
't':'∫Âø¿',
's':'•‰•Ø•Î•»',
'd':'√Ê∆¸',
'h':'•Ω•’•»•–•Û•Ø',
'e':'≥⁄≈∑',
'f':'∆¸ÀЕœ•ý',
'l':'¿æ…',
'db':'DeNA',
'm':'•Ì•√•∆',
'bs':'•™•Í•√•Ø•π',
'g':'µøÕ',
'c':'π≠≈Á',
}
head = "Subject, Start Date, Start Time, End Date, End Time, Description, Location"
print(head)
month_days = {'03':'31', '04':'30', '05':'31', '06':'30', '07':'31', '08':'31', '09':'30'}
for month in month_days.keys():
data.setdefault(month, {})
for day in range(int(month_days[month])):
data[month].setdefault(day + 1, {})
data[month][day + 1].setdefault('date', '2019/' + month + "/" + ('0' + str(day + 1))[-2:])
for month in month_days.keys():
html = urllib.request.urlopen("https://m.hanshintigers.jp/game/schedule/2019/" + month + ".html")
soup = BeautifulSoup(html, features="lxml")
day = 1
for tag in soup.select('li.box_right.gameinfo'):
text = re.sub(' +', '', tag.text)
info = text.split("\n")
if len(info) > 3:
if info[1] == '\xa0':
info[1] = ''
data[month][day].setdefault('gameinfo', info[1])
data[month][day].setdefault('start', info[2])
data[month][day].setdefault('stadium', info[3])
if re.match('•™°º•Î•π•ø°º•≤°º•ý', info[2]):
data[month][day]['gameinfo'] = info[2]
data[month][day]['start'] = '18:00'
text = str(tag.div)
if text:
m = re.match(r'^.*"nologo">(\w+)<.*$', text, flags=(re.MULTILINE|re.DOTALL))
if m:
gameinfo = m.group(1)
data[month][day].setdefault('gameinfo', gameinfo)
m = re.match(r'^.*"logo_left (\w+)">.*$', text, flags=(re.MULTILINE|re.DOTALL))
if m:
team1 = m.group(1)
data[month][day].setdefault('team1', team[team1])
m = re.match(r'^.*"logo_right (\w+)">.*$', text, flags=(re.MULTILINE|re.DOTALL))
if m:
team2 = m.group(1)
data[month][day].setdefault('team2', team[team2])
day += 1
for month in month_days.keys():
for day in data[month].keys():
if data[month][day].get('start'):
m = re.match(r'(\d+):(\d+)', data[month][day]['start'])
if m:
sthr = m.group(1)
stmn = m.group(2)
start = datetime.datetime(2019, int(month), int(day), int(sthr), int(stmn), 0)
delta = datetime.timedelta(hours=4)
end = start + delta
sttm = start.strftime("%H:%M:%S")
entm = end.strftime("%H:%M:%S")
summary = ''
if data[month][day]['gameinfo']:
summary = data[month][day]['gameinfo'] + " "
if not re.match('•™°º•Î•π•ø°º•≤°º•ý', data[month][day]['gameinfo']):
summary += data[month][day]['team1'] + "¬–" + data[month][day]['team2']
#head = "Subject, Start Date, Start Time, End Date, End Time, Description, Location"
print(f"{summary}, {data[month][day]['date']}, {sttm}, {data[month][day]['date']}, {entm}, {summary}, {data[month][day]['stadium']}")
°°ª»§§ ˝§œ°÷./scrapingtigers.py°◊§»º¬π‘§π§Î§¿§±°£
°°3∑Ó§´§È§Œæ Û§Ú•π•Ø•Ï•§•‘•Û•∞§∑§∆§§§Î° 2∑Ó§Œ•§•Ÿ•Û•»§œ§π§«§ÀΩ™§Ô§√§∆§∑§Þ§√§ø§»∏¿§¶§≥§»§‚§¢§Î§¨°¢2∑Ó§À§œ°¢µØ∞°•ø•§•¨°º•π¡ÍºÍ§ŒŒ˝Ω¨ªÓπÁ§»§´°¢π»«Ú¿Ô§»§´°¢•§•Ï•Æ•Â•È°º§ ΩËÕ˝§¨…¨Õ◊§ •§•Ÿ•Û•»§¨§¢§Í°¢§Ω§Ï§È§¨ÃµªÎ§«§≠§Î§»§¶§Ï§∑§§§»§§§¶§≥§»§‚§¢§Î°À°£
°°§Þ§ø°¢•™°º•◊•Û¿Ô°¢∏ڌƿԧŒæÏπÁ§œ°¢•§•Ÿ•Û•»Ã槌∆¨§À§Ω§Ï§æ§Ï°÷•™°º•◊•Û¿Ô°◊°÷∏ڌƿ԰◊§»…Ωº®§µ§Ï§Î°£
°°§µ§È§À§œ°¢ªÓπÁ≥´ªœª˛πÔ§¨…‘ÿ§¿§»•§•Ÿ•Û•»§»§∑§∆≈–œø§«§≠§ §§§ø§·°¢•™°º•Î•π•ø°º•≤°º•ý§ŒªÓπÁ≥´ªœ§œæ°ºÍ§À18ª˛§»§∑§ø°£
°°Ω–Œœ∑Î≤çÚcsv•’•°•§•Î§»§∑§∆ ð¬∏§∑°¢Google•´•Ï•Û•¿°º§À•§•Û•ð°º•»§π§Ï§–OK°£